My big problem with Statista
Your Web search for data will often land on statista.com. Unless you’re a member, though, the data will be missing the source — which makes it worse than useless. Statista’s policies undermine the integrity of research and data and contribute to the flood of bad statistics and dubious surveys you read in media.
Let’s take an example. While researching an article, I Googled “share of internet users who get news from social media sites.” Google provided the following featured snippet:
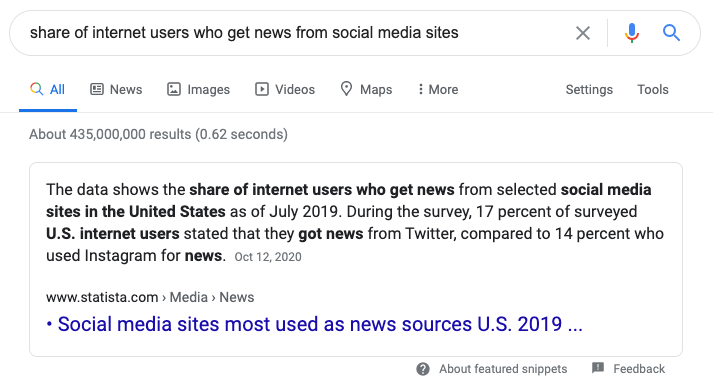
Like many searches for survey and other statistics, this search lands on Statista. This is no coincidence — Statista’s visibility at the top of statistics searches is, I’m certain, a result of significant effort in search optimization on the part of the company.
When you click on the link, you see this:
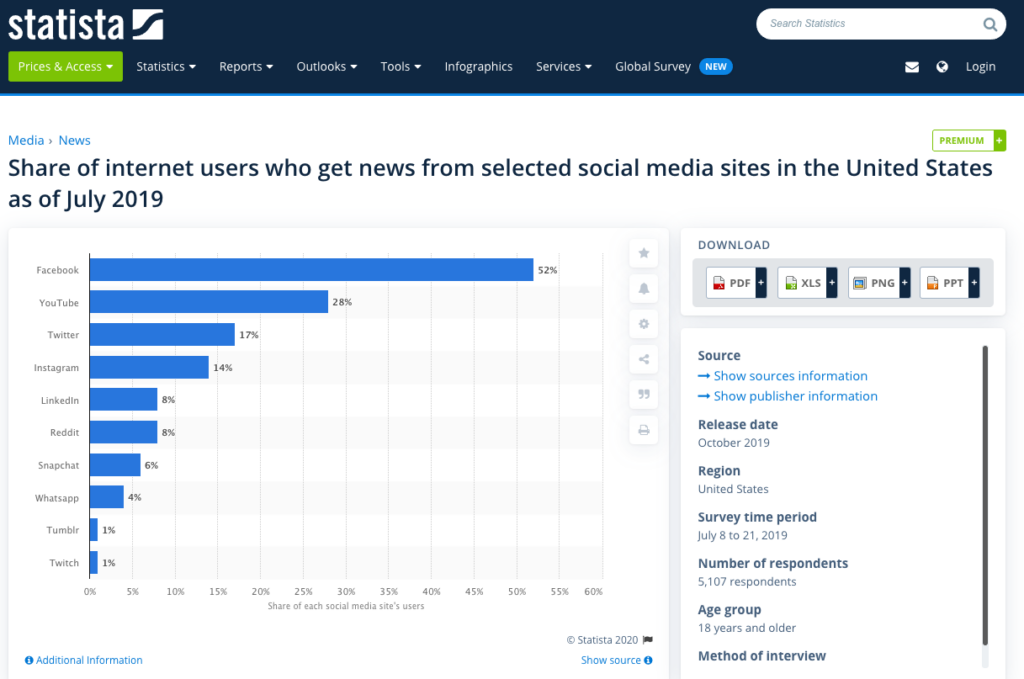
Hurrah! A cool bar chart. Just clip it and paste it into whatever you’re working on — or just cite a number — and you’re done, right? Or if you’re not quite that sloppy and are trying to do the right thing, maybe you put “Source: Statista” in whatever you’re working on.
But the source is not actually Statista — Statista didn’t do the survey, it is just an aggregator. Somebody else did the study. If we want to judge the credibility, we need to know who conducted the research, when, and how.
We can see from the box on the right that this data comes from a survey conducted in July of 2019 with 5,107 respondents. But who conducted it? Unless you are a paying subscriber of Statista, if you click on “Show sources information,” you hit a paywall that displays this message:

So you need to sign up to pay $468 a year to find the source. Maybe 1% of those landing on a statistic like this will do that. The rest will just settle for “Source: Statista” or omit the source altogether.
Why don’t they just show the source link outside the paywall? Because if they did, you’d click away and forget about Statista. They’d rather have a small chance to get your subscription money than do the right thing as a responsible research should.
Not providing the source link is malpractice. And Statista is not only making it easy to falsely cite them as the source, they’re actively discouraging people from finding the original source.
Finding the original source
If you go back to the original Google search, you’ll also see a link to a report by Pew Research Center, called “Americans Are Wary of the Role Social Media Sites Play in Delivering the News.” Pew is a highly respected, nonprofit, independent research company, and their research methods and analysis are excellent. And Pew makes all of its research available for free. Its report is full of valuable and detailed information on Americans’ behaviors around news and social media. If you dig into the report a bit, you find this graphic:
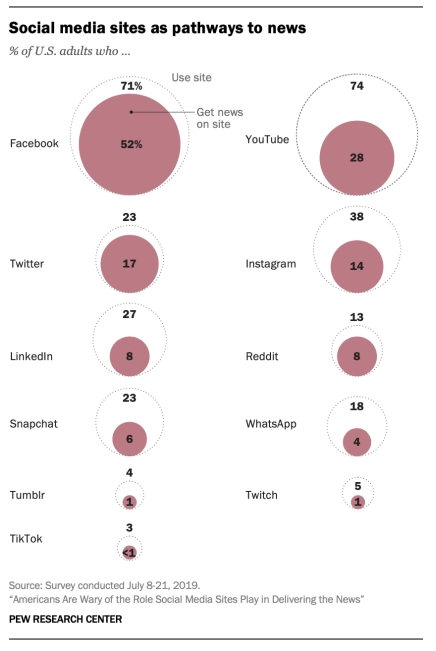
Clearly, this is where Statista got its data. But even in this graphic, you get a bit more context, namely how many people use each social network site, regardless of whether they’re getting news from it.
Unless you are a premium customer of Statista, you cannot click on their source link to get to this research. It’s fine for Statista to show statistics from Pew (provided they have permission, of course). But if you’re showing statistics that you didn’t create, you should always provide the original source, with a link, so readers can judge the credibility of the data. It’s also the right thing to do to give appropriate credit to the original researchers.
Statista is undermining the integrity of statistics
I have nothing but admiration for diligent researchers at Pew, universities, and reputable private research companies like Edison Research and Forrester. These companies and organizations invest significant effort and resources in generating primary data that we can use to make decisions. If you want to share research from such sources, you must cite the source and provide a link. It will add to your own credibility and provide the credit that such companies deserve for their work. (Every link you provide adds to the researchers’ reputation, as it should.)
I have no issue with Statista aggregating statistics, with appropriate permission, and charging a subscription for that. The aggregation serves a useful function.
But I have two problems with the role Statista now plays in the research ecosystem.
First, like any other organization that cites research, they should provide a link to the original source — outside the paywall. Failing to name the source or provide a link is research malpractice. Shame on them.
Second, Google should deprecate Statista links until they change their policy. Google’s snippet link to this research is a key element contributing to Statista’s role in the spread of unsourced research. Shame on them, too.
Until this changes, the responsibility lies with you as you use the Web to source research. Always look for the original source. And if you omit the citation — or just write “Source: Statista” — we’ll know you’re too lazy to do the necessary work to verify where your stats are are coming from. That reflects poorly, not just on Statista, but on you.
Once again, you are scaring me. I encountered the same issue last week. As a Band-Aid, use a negative keyword
You nailed it. That has always bothered me about Statista, but you articulated it perfectly. They’re NOT a source. They’re an aggregator most likely ripping off other people’s research the same way Google rips off news sites. No wonder Google smiles on them, they’re in the same game. And you never know whether some money has changed hands to put Statista so high in the rankings either. Just saying.
I disagree that what Statista does is “malpractice.” Apparently Statista aggregates information from other sources and in effect says, “Here’s the information you’re seeking, or at least a chunk of it, but if you want to know the source, whether because you need or should cite to the original source or because you want to do your own investigation into the reliability of what we’re offering here, you have to pay us. Or at least take your valuable additional time to independently find the source we used.” (That’s what Josh did in his 12/7/2020 example. He found the Pew survey that was Statista’s source.)
I myself am not a consumer of Statista information, so far as I know, but I fail to understand why, at least as to the end user, this is either malpractice or unethical. The world is filled with information, some accessible without having to pay for it, some available only if someone pays for it. I’d love to never have to pay for information myself, but I acknowledge that creating information costs the creator, whether the creator is an original creator or an aggregator. The creator or aggregator is entitled to find ways to recoup those costs, possibly even at a profit.
As to whether what Statista does is an unethical rip-off of the original sources of information, that’s a separate question and an important one, but I’m focusing here on whether the end user is entitled to all the information Statista aggregates without any cost to the end user. I fail to understand why.
I do pay for some information, e.g., The New York Times online, the Los Angeles Times online and in print. Why is what Statista does less ethical than the Washington Post in saying that if I want to see some of their information, I have to pay to see it?
I’ve used public libraries, but even though I don’t pay directly for that use, I and everyone else pays for that through taxes. (And happily, I might add. Libraries are a great use of my taxes.) Libraries are aggregators too. Somebody’s paying.
I don’t know why the misuse or abuse of Statista’s free information is Statista’s fault. Maybe you can explain.
Keith, my answer is a little different from Gordon’s below.
There is an ironclad principle for all researchers, academics, and writers: if you use data, you must provide the source (and in this day and age, link to it). There are two reasons.
First, it acknowledges the effort that the original creator of the data put in, which is often significant (surveys are not cheap, neither are detailed statistical analyses). This is a question of giving credit where credit is due. It’s no different from recording a song and not crediting the original composer.
Second, it does a service to the reader. The reader can look at the data and say “Ah, this is from Pew, so I trust it.” Furthermore, that reader can actually click through and find the original Pew study and learn more. Or the reader may look at the source and say “No, this was done by a sloppy and biased researcher, and I don’t trust it.”
If you “break the chain” by leaving the source out (or hiding it behind a paywall), the data is useless. Without knowing where it came from, it is of no value. And if you make it hard to find the source, you encourage fast and cursory researchers (of which there are many) to cite it without identifying the source, which makes the useless and contextless statistic spread further.
You wash your hands; you say “thank you” when you get a gift; you site sources properly. This is how researchers and writers do their work.
I want to be clear. A lot of what Statista does is fine. Aggregating data to make search easy is fine (although Gordon would potentially disagree). Making a nice visual presentation of it is fine. Charging for access to the whole collection is fine. But showing the data and hiding the source is unethical. And that’s my problem with Statista, which, as an important participant in the research ecosystem, really ought to know better.
I still think it’s unethical.
If you want to put advanced statistics and data sets behind a pay wall, that’s one thing, but to not even cite your source, when the entire body of journalism does, it’s kind of unheard of. It’s not even their data to hide. And given Statista’s popularity, this is going to create, excuse me, they ARE creating an epidemic of people blindly citing Statista as their source. As I wrote in the previous post, a very popular Podcaster used Statista as a source, thinking that they somehow conduct their own research.
Clearly, Statista is of the same beliefs that you subscribed to, but I think there should be more done, so people aren’t misled. In place of where there is usually a citation, it should clearly state STATISTA IS AN AGGREGATOR – SUBSCRIBE FOR THE SOURCE”
So, Statista is a business. Businesses need to make money. Centers like Pew etc, are nonprofits that receive funding from other sources. Long story short, good data isn’t free. Aggregation is a great time saver, probably saving one more dollars in time if you were to go “free” sources to get what you need all served up on a plate for you. No one owes us free data. So my two cents, you can cook the turkey dinner from scratch yourself, or go get it at a nice reputable restaurant. Spend your money where you feel it is best spent, sorting through free data yourself, or pay an aggregator to save you time.
So I ask, how would your propose Statista make its money? I use data all the time, but I am also an entrepreneur. So, I get their business model. It’s actually pretty brilliant. What are your thoughts?
Good data is an abundance. The last 20 years of Internet has shown that
Good questions, Keith. To me, the point is that the ORIGINAL source invested far more time and effort to develop the information, by taking a survey, running some analysis, or thinking deeply about some issue. All these take tremendous human effort. All Statista does is to “scrape” someone else’s content off the web, put up a paywell, and work on getting high in the search engine results.
This is analogous to newspapers who pay actual human journalists to create original stories, only to have Google come along, scrape off the headlines, and sell ads around those. For far less investment, the aggregators grab someone else’s content and monetize it, arguably more effectively than the original sources do. Yes, they put in some effort, but the benefit they derive is out of all proportion to the original effort required to generate that information in the first place. Does that make sense?
Gordon and Josh both raise important issues. In the best of all worlds, everyone gets the information they need, which includes source credits, and everybody gets fairly compensated for their contributions to the production and distribution of information. Unfortunately, this is not the best of all worlds. (Though not the worst, either. Thank you, U.S. voters.)
I don’t see obvious remedies for either the problems created by Statista’s practice of not disclosing the sources of its information without extracting payment for that source information or the financial impact on original producers of information caused by information aggregators such as Google. At least in the United States there are fundamental Constitutional limits on possible solutions to these problems. Maybe things can be improved, but if improvement is to come via regulation, it can’t go as far as you might like.
I think the point is not that they are using that medium to charge.
they may have taken someone else’s data, done some self-analysis and paywalled it.
I think that a reduction in their subscription charges will not only add them in everyone’s good books but also increase their inflow of subscribers which would finally help their end goal of earning more revenue. This way even researchers will be happier then they feel now.
i am a researcher from 2nd world country and trust me, Statista’s annual subscription charges could fund 2-3 of my high end prospective research.
To prove my facts, just look at Quillbot and marketingcharts. They are getting more and more preferred by GenY and GenZ researchers. If you had seen them few years at their initial days, their inflow was significantly low.
In the End, I will say that statista may have the largest database of accumulated survey reports but several database are catching on to them and marketingcharts is one of them.
An obvious remedy, is to inform readers, so they don’t go around blindly citing Statista as a source.
In place of where there is usually a citation, they should include: “STATISTA IS AN AGGREGATOR. SUBSCRIBE FOR THE SOURCE.“
Isn’t another way of putting it that they don’t offer anything at all for free, but some people don’t understand that the source is an essential part of the product?
It’s a bit like if a publisher offered their novels on their website, but with every third page missing. If some people simply did without those pages, I think we’d regard it as a basic misunderstanding. What those readers would consider to be the novel would not actually be the novel. They wouldn’t have read it.
Statistics are kind of unusual in that a description of the product for advertising’s sake can resemble the entirety, but the source is essential for it to be worth anything.
It’s also kind of strange that if I see unsourced information on Statista, I can reasonably become somewhat more confident that it is true, and even if I pay for the source, I still can’t be entirely confident it is true. If it’s something I had no idea about previously, there may be a bigger gap from total ignorance to unjustified knowledge than from there to greater confidence. A lot depends on how much is at stake, and whether Statista does a good job of collecting.
Hello!
I’m doing a research project for my high school history class, and I wanted to know where statista got a certain piece of information from, to see if it got it from a reliable place, and I found it a little bit weird how I had to pay to see where they got their information from. What if I paid and the place they got their info from wasn’t reliable? But oh well.
Y’all in the comments can argue all you want about how Statista should be allowed to do this because they’re putting in “so much effort” in finding this info. But the people who made these infos, and might I say: for free, are the ones who should be earning the money; not statista for grabbing these resources, putting them together, and then making you pay for it! That’s exploitative in my opinion. Anyways, the info I need for my project is pretty generic so I’m using BLS and jstor. I also use less known sources that provide a lot of evidence unlike large sources like Statista that don’t even show the freaking original source… Peace out.
Also, sorry for being a little informal.
Don’t pay for Statista, just Google to find their sources. I don’t know who can afford it anymore since the rate hike, (it’s now $99/mo, ouch!) My guess is that they cater to corporations, high paid journalists, law-enforcement, and well funded scientists.
Thanks a lot for your post..highly appreciate it.
I’ve got guest account for free from statista this morning, and will skip it after read this post.
– If this life too short, let’s continue do the right thing –
While Statista continues its dubious practice of publishing data without attribution, the mere fact that it has published that data in the first place is, in an indirect kind of way, quite useful, as it means that very same data is likely out there and freely available for the taking with proper acknowledgement, often from the original source.
It is just annoying that a purveyor of second-hand information that does not acknowledge the source of the data in its online publication of that data gets top Google billing while the very same data it has used is often less prominent or difficult to locate in Google’s search results, with the consequence–and one might suspect not entirely by accident–that it has assumed de facto ownership of that data; everywhere one looks these days one runs across some or other piece of information saying “Source: Statista.”
Congratulation for the review on Statista. As a scientist, it always disturbs me to get stats without having the proper source and reliable methodology in place. If you deep dive their “findings”, you will even notice that the numbers they present are frequently contradictory. Cheers,
Statista is a sham. They generate €60 million in revenue. To get that sweet moolah, they have to hide their sources (which are free). For all intents and purposes, unless you are paying these grifters hundreds of euros every year, they can make up any graph they like because you aren’t owed the source. There are dozens of types of statistics misuse, there is no way they can be detected without being able to vet the data. This is integrity 101.
I can tell you that as a paying subscriber to Statista, it gets worse!
Much worse.
They have told me that unless I increase my membership to the industry level, I am not allowed to publish any of the data I get from Statista.
That means that I am now in an agreement to not share what I learned from the data on my blog, or in my YouTube videos, or anywhere else except my private notes.
I am worse off than I was before I paid them $664 per year.
Not only that but it took me two weeks to get an answer to this question from support and my ‘dedicated’ rep has only answered one email and that took weeks as well. You will get almost no support. I asked if I could get a refund and they replied 12 days later that “my request to cancel my renewal for next year will be considered”
Yes, you read that right. No refund, and they will consider whether I can cancel next years payment.
You are better off finding the data with Google, then at least you will be allowed to talk about it.
I agree with you 100%. Shame on them for not even providing a source.
Just today, I was watching a PBD’s Podcast on FBI whistleblowers where Patrick cited a Statista poll “This isn’t some FOX News poll, THIS IS STATISTA!” https://www.youtube.com/live/Md1Ww2U0G-E?feature=share&t=4090
So I started thinking: “Could Statista be bias?” and now that I understand how they work, it’s actually WORSE than bias, they’re motivated by money. And because they have a financial incentive to keep their sources secret, people will do exactly as you said and blindly site Statista as their source. That’s horrible!
They’ve also increased the subscription to $99/mo (but advertise it as being on sale for $79/mo). So basically, they’re just spammers. At this point, I don’t think it’s ethical to cite statista as a source, so I’ve added them to my Ublacklist filters. (GOODBYE FOREVER!)
Also, you have a typo on your last paragraph: “the responsibility likes with you”