Wordle: Revised mathematical analysis of the first guess
Yesterday’s mathematical analysis of the popular word puzzle Wordle was flawed. It assumed that the words used in the puzzle were similar to other word lists, but they’re not — and that changes everything.
What word list does Wordle use — and why does that matter?
Wordle actually uses two word lists (or properly speaking, lexicons). There is a list of over 10,000 legal English words that are appropriate for guesses. And there is a shorter list of 2315 potential solutions to the puzzle. The short list is carefully and idiosyncratically curated to include only common and familiar words, and it apparently omits plurals like TUCKS.
I had assumed that both lists were private and inaccessible, but the internet quickly informed me that they are actually in the Javascript code that the Wordle site uses. (Spoiler warning: if you search this information out, you may find all the daily solutions listed in order, which will ruin the game for you.) Fortunately for me, others have extracted and published these lists.
It only took a small modification to my Python code to analyze the new lists. And it made a dramatic difference, because the letter frequencies in the Wordle solutions list are very different from the letter frequencies in the Scrabble list I’d been using.
Revised letter frequencies suggest a different first guess.
Here’s a chart of the letter frequencies in the list of Wordle solutions:
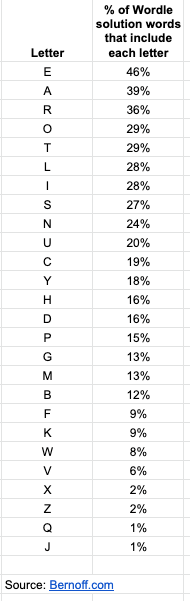
While E appears in the most words, this is not the same frequency list as ordinary English, which begins ETAOIN. And it is also different from the frequencies in the Scrabble list, in which S is the most popular letter because of all the plurals.
A first guess based on these letters would include the letters EAROT. ORATE comes to mind. This is a pretty good first guess, since it will tell you about the three most common vowels immediately, along with the frequently occurring R and T.
However, as we learned yesterday, if you want your guess to have a higher likelihood of direct hits (letters in the right place), you need to look at frequencies in each of the five letter positions.
Here’s how that looks for the new list of solution words:
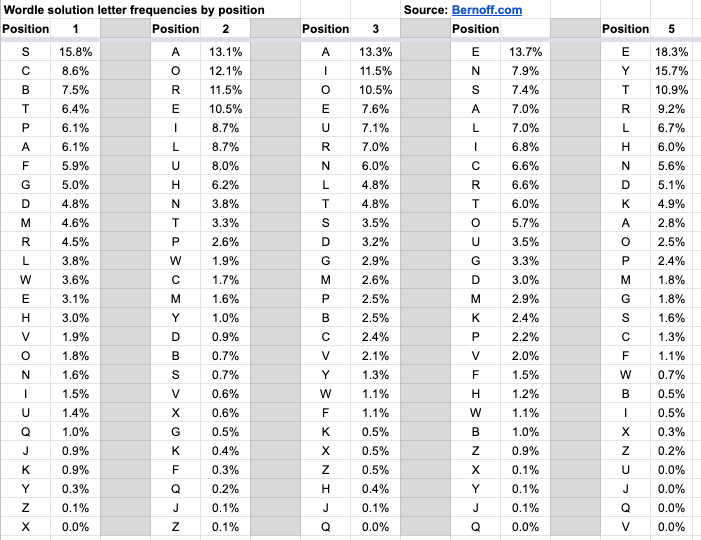
So the “word” most likely to get direct hits is SAAEE — which is not an actual valid guess. Looking at these frequencies, a good guess word should start with S and end in E, and include an A in the middle.
SAINE (to make the sign of the cross) and SOARE (an obsolete word for a young hawk) are good candidates, if you don’t mind guessing archaic or obsolete words. Other potential choices that aren’t so arcane are SANER, SAINT, or SLATE.
The brute force method reveals the best guesses
With a slight tweak to the code, I tested every possible guess against every possible solution. The results were enlightening.

If you want to maximize the chances of getting any hits at all, you’ll guess URAEI, which is the plural of “uraeus,” which is the snaky thing on top of Egyptian sarcophagi. (That’s one new fact you learned today!) You could also guess its anagram AUREI (ancient Roman gold coins). Each has a 95% chance of generating a hit, and each will give you information about the vowels A, E, I, and U, and with a higher hit rate than ADIEU. ALOES and ADIEU have a respectable 93% hit rate.
If you want to maximize the chances of getting exact matches (right letter in the right place), your best choices are SOOEY (a hog call), SAREE (alternate spelling of SARI, the common Indian garment), SOREE (an obsolete name for a bird), SIREE (as in “Yes, siree!”), and SEMEE (a spotted field in heraldry). That last is just apparently what happens when you fling as many E’s as possible into one word. Unless you get your thrills from direct hits, I wouldn’t recommend any of these words, as the double letters mean you’ll get information only three or four different letters in these guesses, when you could be finding out about five.
If you want to maximize the total number of matches in the word (as opposed to the chance for getting one match), you’ll pick one of the anagrams ORATE (speak formally in front of a group), OATER (Hollywood slang for a Western), or ROATE (to learn by repetition). Each will get you an average of 1.79 hits per guess. Close behind are REALO (a German politician who is a Green, but moderate), ARTEL (a Russian crafts cooperative), TALER (old German coins), RATEL (a type of badger), TERAI (a wide-brimmed hat), and RETIA (a type of yarn). Can you feel your vocabulary growing?
The best guess, according to my combined score
I value letters in position as twice as much as letters out of position, since they seriously help you narrow down your guesses. Based on that score, what are the most valuable guesses? Here’s the list, best guesses first:
SOARE (young hawk)
ROATE (learn by repetition)
RAILE (to flow steadily)
SAINE (to make the sign of the cross)
ORATE (to speak formally)
STRAE (straw, in Scottish dialect)
RAINE (a kingdom)
SLANE (a spade for cutting turf)
SALET (a helmet that covers the back of your neck)
ARIEL (an African gazelle — the Disney princess is a proper noun and therefore not relevant in this context)
Here’s why I like SOARE. It includes four of the five most popular letters, and will tell you right away about the three most popular vowels. It begins with S and ends with E, the two highest-likelihood letters in position, so there’s a decent chance you’ll know how your solution word begins and ends. It is a complete miss only 8% of the time. Half the time it will get you a letter in the right place, and will generate an average of 1.77 hits. And finally, it will get you a shot at 11 near matches (that is, either four hits with three in the right place, or five hits with two in the right place): SCARE, SCORE, SHARE, SHORE, SNARE, SNORE, SPARE, SPORE, STARE, STORE, and SWORE.
If you’re allergic to obsolete words, I suppose you could try ORATE. But surprisingly, none of these ten highest-scoring words is in the list of solutions, not even ORATE, which ought to be. In fact, none of the top 800 best guesses are in the list of solutions, because many of them are plurals, end in “ed,” or end in “er.”
I look forward to your insights on this revision based on the real Wordle data. What has been your experience?
This approach leaves me completely cold. I like five minutes of serendipity in my day. I let “the spirit” move me for my first choice and go from there. It’s just a reminder for me that efficiency isn’ the be all and end all of life.
Hey, the fun part for me was figuring it out. Everybody should feel free to ignore it!
Funny – I’ve been doing both “best choice” (like STARE or RATES, for me) and pick-a-word and see what happens, depending on my morning mood. (PROXY crushed me the other day with that.)
K
Great work, Josh. I guess I’ll be saying “Adios” to adios.
Hey Josh!
Trinket.io lets you post code and easily embed it. I’d love to see how you arrived at your solution. As an amateur Python guy myself, I’ve done this a few times with basketball and Scrabble scripts.
I was thinking about this point this very morning , as today’s word is not one you could use in NYT Spelling bee.
Interesting analysis. But I care much more about consonants than vowels. Knowing the vowels leaves way too many possibilities, but given the consonants, ones brain is likely to fill in the vowels. Consider Hebrew. As a fellow coder I’ve come to realise that analyses like yours are missing a crucial element: what information is useful for a human brain to guess the answer – rather than that required for a Turing machine to calculate it. ; – )
It would seem to me that a better approach than trying to figure out letter combinations would be trying to minimise the number of valid words left in the lost. Better still would be to choose as your starting word the word that minimised the number of guesses you will need to make (either on average or minimising the maximum number of guesses you will need).
I think those all those criteria will be equivalent – depending on how they are measured. As I pointed out before, “the number of guesses you will need to make” is probably different for a computer and a human depending on how we pattern match data (letters we have) to the solution space (words we can think of).
@Nick
My reply was intended to the OP, somehow ended up on your comment, apologies.
I take your point about han vs machine solution, but I’m interested in the hypothetical “optimal” machine solution (given a definition of optimal, which I have described two potential options of). In particular I am interested in the strategy that minimises the number of guesses you will have to make in a “worst case scenario” (i.e. the case where the chosen strategy needs to make the highest number of guesses). While for a specific set of words that may or may not be equivalent to a different strategy, in the general case (i.e. any arbitrary dictionary of allowable letter combinations and wordle puzzle length) they won’t be.
Replying to a reply in a reply to an accidental reply ;-D
Yoni – look here
Tyler Glaiel
(Tyler and Glair are both words)
Dec 30, 2021
There are 2315 possible solutions, and 12972 words it accepts as guesses.
With RAISE as the first guess, you will average 3.49546 guesses to solve on average, only very slightly worse than ROATE, but have that sweet, sweet chance of landing that hole-in-one (1:2315)
This version of the bot finds a solution in 3.49417 guesses on average, and has a worst-case of 5 guesses (meaning, it *always* finds a solution). The ideal first guess using this method is ROATE.
https://medium.com/@tglaiel/the-mathematically-optimal-first-guess-in-wordle-cbcb03c19b0a
Here’s another nice article, kudos that Andrew considers both Easy and Hard mode, however there are some internal inconsistencies (see RAISE) and of course his algorithm may not be as good as the one cited above
https://andrewsteele.co.uk/blog/2022/02/wordle-math-entropy-first-word/
easy mode hard mode
all words common words all words common words
rank word turns to win word turns to win word turns to win word turns to win
1. REAST 3.604 TRACE 3.625 TRAPE 3.805 TRACE 3.840
2. TRACE 3.608 CRANE 3.635 PRATE 3.808 SLATE 3.841
3. CRANE 3.610 ROAST 3.638 SALET 3.811 LEAST 3.846
<>
Please review the algorithm you “hacked mercilessly”, you should be able to reproduce or refute the above. And have a look at why you have RAISE in both feasible and unfeasible test words.
easy mode
ROATE 3.638 – not solution set
RAISE 3.641 – not solution set
RAISE 3.669 – potential solution
hard mode
ROATE 3.850 – not solution set
RAISE 3.889 – not solution set
RAISE 3.928 – potential solution
@Yoni
re:> In particular I am interested in the strategy that minimises the number of guesses you will have to make in a “worst case scenario” (i.e. the case where the chosen strategy needs to make the highest number of guesses).
Well, here’s a nice strategy, if *ILLS is the “worst case scenario” then you need to burn the first five guesses as follows :
LARNT (require L (yellow) to proceed)
SPICK (require S,I (yellow) to proceed)
WEMBS (S green, 2-4 non green)
VOZHD ( 2-5 non green)
FUGLY ( L green; 2,3,5 non green)
which perfectly isolate the 19 _ILLS words from each other and all other wordle words.
(The 7 invalid *ILLS first letters can also be factored into the proceed gates above, and below).
Once off the previous sequence, jump to the following. The guess spent on SPICK may mean recovery is not possible though (in that case may mean more than 6 guesses ?)
If LARNT (proceed on * * * * Y)
SHOES (proceed on Y * * Y G)
TOWZY (proceed on Y * * * *)
KOPJE (proceed on * * * * Y)
BEFOG (proceed on * G * * *)
which perfectly isolate the 15 _ESTS words from each other and all other wordle words.
I’m a newby and I agree with you. My bane is R and E. I started using AROSE without any investigation into the vast WORDLE milieu. I got my first R and E on my second game. Since I never considered Not Using the R and E on my second guess, I pretty much used up all the blank space on my crossword puzzle book page with words beginning or ending with RE and ER. SOARE didn’t help although I do like the S up front. I’m thinking ov going with SEWER just to prevent the dreaded ER. Any comments?
I appreciate your analysis on the best opener word. I also did a whole bunch of similar analysis using the same word lists (I posted an article on my Linkedin). Unless I reveal 3+ letters from first word, I have always had a preference for opening with two non-overlapping words to get the most information available. From this strategy, I’ve been able to solve more than one-half of puzzles on Word 3.
My data considered both overall letter usage frequency and letter positioning frequency. Using the much larger word list, I found the two best opening words to obtain the most information is SANER & DOILY. If using only Wordle’s solutions list, the two best openers are SLATE & CRONY.
If you used SOARE, as you suggest, the best 2nd word to use would be LINTY. When scoring the words back to the solutions list, SLATE & CRONY slightly edge SOARE & LINTY on percentage of solutions with at least one letter in the correct position, average number of letters in correct position, and average number of letters revealed (regardless of position). However, SOARE & LINTY has an advantage that 3 more letters will be revealed in 75% of solutions versus 69% of solutions using SLATE & CRONY.
I really like Y. I think it fills in nicely for I in sounding out words. However, if you get a hit on the E in position 5 the Y is useless in the second word because the only words that have a Y with the E at the end are CYCLE and THYME!
So far I sense a general bias towards including C, K, P, W ,D, L, J, M, G, H, etc. Also a slight preference for single vowel words. It seems rare that letters are doubled up…only happened once while I’ve been playing. Seems to like unusual vowel sequences LD, NT.
My strategy is an elimination method. Narrowing on included vowels and eliminating R S & T. I was using words with A and E in my first guess e.g. TEARY followed by PIOUS. Then, informed by the above general sense of bias towards scrabble score letters of 2 and above I’ve started including those in my first guess e.g BLEAK then mostly PIOUS (old habits die hard) or MOUSY
I’ve rarely hit more than one letter in the first guess which serves my elimination strategy well. So far I haven’t failed to solve it.. Only one 5 and scored 4 (mostly) or better in my 16 games.
Others in my Wordle share group regularly hit 2 included or in place letters on their first word and regularly solve in 3.
but overall weighted average scores are similar. Some claim a mysterious insight into the mood of the Wordle gods. Today one posted a 2 after a first 2 letters in place start. I was highly suspicious.
Ploughing ahead, I entered FRAIL scoring 2 included letters on my first guess of game 226. informed by my letter bias theories I correctly guessed the word in guess 2! The scores in my group today were 2, 2, 2 and a 3!
Is this down to brilliance, luck, clairvoyance or cheating?
Thanks for the analysis! What I’m looking for is Wordle statistics which will take into account the likelihood of people coming up with follow-up words. I think (correct me if I’m wrong) that getting the most letters in the first word is not necessarily the best metric, if the chance of finding a useful follow-up words are low. It is much more likely that I will think of the word “Snail” as a second, third, or fourth word guess than of the word “Aurei”, and I think that the most useful words for human solvers need to be found using such an approach. e.g., using the frequency of each word (or derivative words like singular/plural of the same noun) in a large corpus of “people-level” texts.
An entropy-based analysis produces very nearly the same top words.
Going with SOARE as word #1, the entropy-based analysis offers these options for word #2:
—– => clint
—-e => teind
—-E => guilt
—r- => glint
—re => tined
—rE => pudic
—R- => fitch
—Re => delft
—RE => abets
–a– => clint
–a-e => tepal
–a-E => gault
–ar- => riyal
–are => talar
–arE => barca
–aR- => humic
–aRe => altar
–aRE => aalii
–A– => clink
–A-e => depth
–A-E => glitz
–Ar- => clint
–Are => ached
–ArE => diact
–AR- => dhuti
–ARe => lathy
–ARE => abaft
-o— => clint
-o–e => lento
-o–E => bling
-o-r- => cutin
-o-re => trued
-o-rE => pownd
-o-R- => acidy
-o-Re => abeam
-o-RE => aahed
-oa– => cloot
-oa-e => abcee
-oa-E => bundt
-oar- => maron
-oaR- => abaca
-oaRe => OPERA ***
-oaRE => ADORE ***
-oA– => PIANO ***
-oA-E => OVATE ***
-oAr- => BRAVO ***
-oAR- => OVARY ***
-O— => culty
-O–e => meynt
-O–E => cloud
-O-r- => cyton
-O-re => rewth
-O-rE => faugh
-O-R- => adult
-Oa– => liman
-Oar- => balmy
-OaR- => COBRA ***
-OA– => acyls
-OAr- => ROACH ***
-OAR- => aahed
s—- => mythi
s—e => teugh
s—E => cunit
s–r- => cruft
s–re => richt
s–rE => centu
s–R- => USURP ***
s-a– => linty
s-a-e => ajwan
s-a-E => thump
s-ar- => abamp
s-arE => aalii
s-A– => chals
s-A-e => bufty
s-A-E => belch
s-Ar- => bachs
s-ArE => ERASE ***
so— => agloo
so–e => aahed
so–E => aitch
so-r- => acids
so-re => VERSO ***
so-rE => PROSE ***
soa– => aalii
soar- => ARSON ***
soarE => AROSE ***
soA– => CHAOS ***
sO— => fubsy
sO–e => aahed
sO–E => pilum
sO-r- => about
sO-re => aalii
sO-rE => aargh
sOA– => abaca
sOAr- => ROAST ***
S—- => thilk
S—e => clipt
S—E => pling
S–r- => butch
S–re => rerun
S–rE => becap
S–R- => filth
S–Re => aarti
S–RE => aahed
S-a– => dault
S-a-e => dempt
S-a-E => ablet
S-ar- => cuppy
S-are => enmew
S-A– => thilk
S-A-E => thilk
S-Ar- => STAIR ***
S-AR- => chapt
S-ARE => chant
So— => cloot
So–E => knelt
So-r- => SCOUR ***
So-R- => chant
So-RE => chant
Soa– => ablow
Soar- => SAVOR ***
SO— => atony
SO–E => SOLVE ***
SO-re => abaca
SO-R- => SORRY ***
SOar- => aalii
SOA– => SOAPY ***
In the first column, capitals = green, lowercase = yellow, dash = grey (unmatched). Asterisks indicate the only possible answer, where that happens to be the case.
Enjoy.
This is really incredible.Definitely takes my analysis for two best starters to another level. It’s interesting that some apparently try to find out as much new information as possible with the second word and others go for the win. My personal preference would be to exclude words with duplicating letters
Some of the suggested words really are unusual to me for the information you already know (SOar- => aalii). Assuming the list of possible words with SOar- is fairly limited, it seems to be more reasonable to limit the list to those with SO start that also contain an A & R.
Nice analysis Jon0
Like the *** touch too.
You almost need two phones to play now though, one with the entropy app running, the other with a human playing for fun.
My main interest in starting an analysis is to see if friends and family playing “man-wordle” with words I choose have an uncanny knack of getting my word in under 4 guesses. Wanted to do a probability analysis of their guesses, specially the final correct guess
I did my analysis based on how frequent letters are in 5-letter words and got
S = 10.28%
E = 10.27%
A = 9.24%
O = 6.84%
R = 6.41%
Ignoring repeating letters and order that the letters appear in, I found that the three best are SOARE, AROSE, and AEROS. Theoretically, if you use any of these words, the probability of getting at least one yellow or green letter is
95.15%. Again, not accounting for repeating letters, but that would have a tiny effect on the calculation.
Sanity check: aren’t ariels native to Arabia? It says Africa up there.
Both. See https://animalia.bio/dorcas-gazelle